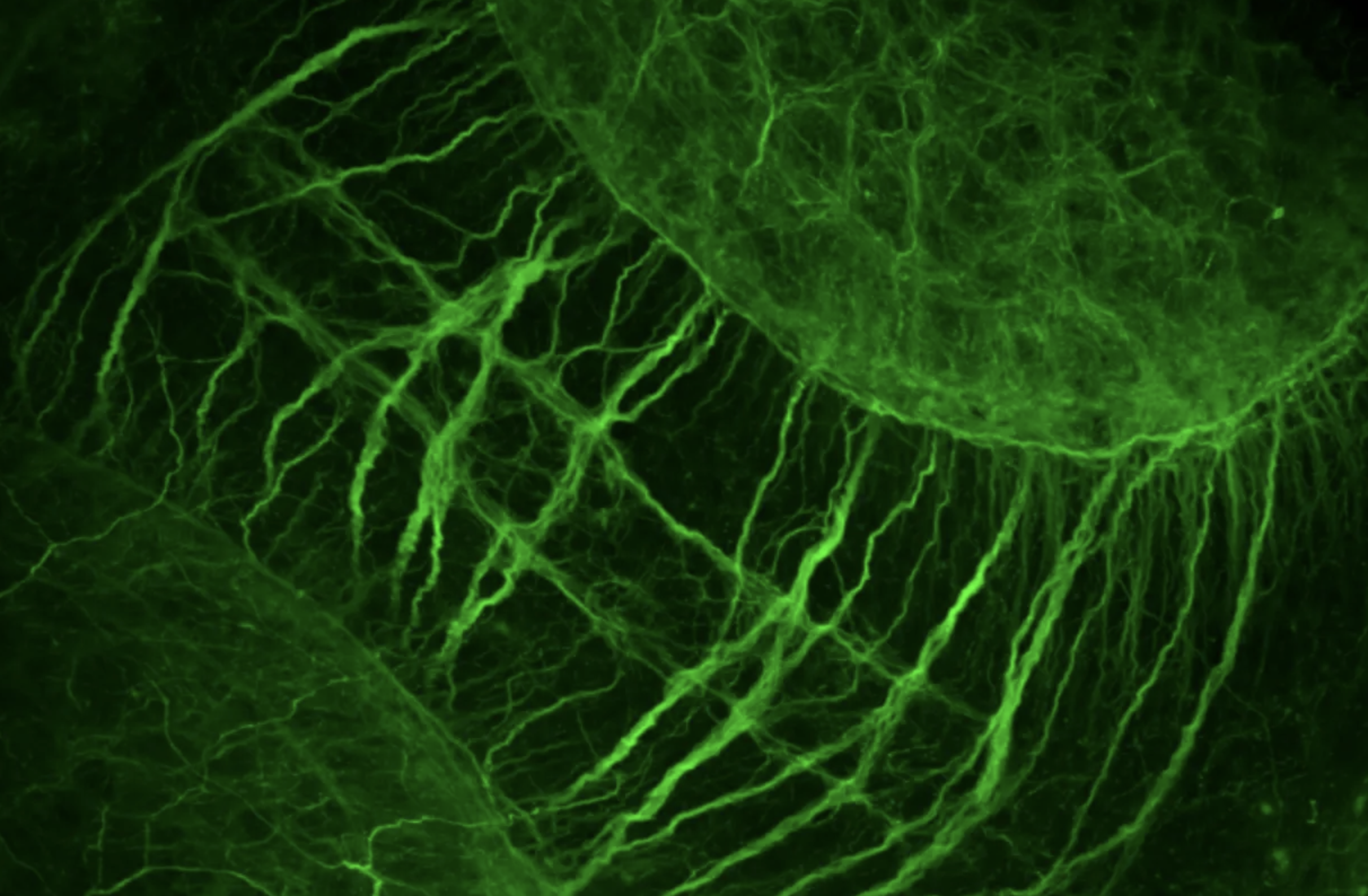
 Macroscopic Overview Of Zebrafish Brain Neuroanatomy - Will Antcliff, Royal Veterinary College
Macroscopic Overview Of Zebrafish Brain Neuroanatomy - Will Antcliff, Royal Veterinary College
Interesting meeting this week with a PhD student on the Lido programme with RVC got me thinking about LLM’s and image analysis. He has two types of images, blobby ones and spikey ones.
The task isn’t about classifying the image into one or other category, we are interested in trying to quantify a form of “spikeyness”. Researchers can tell the difference between the two types of image, and we can see some of the features that helps us make those distinctions, but they are difficult to describe and quantify.
The discussion about the structural topography of the image and the challenges of identifying where in the images features were being generated led to a discussion around LLM’s and tokens. The observation that you can ask ChatGPT to rewrite a blog like this “in the voice of an American” implies that the tokenisation process has features that describe “Americaness”. Can we use the same approach for looking for features in tokenised pixel data?
One for us to explore with Jack who is doing similar research with time series data on the TRUST2 project. I like this kind of research, being able to explore a hunch and hacking a prototype together.